This section provides brief summaries of selected resources for research that have been published in journals of the Psychonomic Society, typically Behavior Research Methods.
These resources consist of linguistic norms, visual stimuli, novel analysis techniques, software, etc.
If you think one of your articles is worthy of inclusion, please contact the Digital Content Editor.
Measuring Agreement among Several Raters Classifying Subjects into One-or-More (Hierarchical) Categories: A Generalization of Fleiss’ kappa
Filip Moons & Ellen Vandervieren

Cohen’s and Fleiss’ kappa are well-known measures of inter-rater agreement, but they restrict each rater to selecting only one category per subject. This limitation is consequential in contexts where subjects may belong to multiple categories, such as psychiatric diagnoses involving multiple disorders or classifying interview snippets into multiple codes of a codebook. We propose a generalized version of Fleiss’ kappa, which accommodates multiple raters assigning subjects to one or more nominal categories. Our proposed statistic can incorporate category weights based on their importance and account for hierarchical category structures, such as primary disorders with sub-disorders. The new statistic can also manage missing data and variations in the number of raters per subject or category. We review existing methods that allow for multiple category assignments and detail the derivation of our measure, proving its equivalence to Fleiss’ kappa when raters select a single category per subject. The paper discusses the assumptions, premises, and potential paradoxes of the new measure, as well as the range of possible values and guidelines for interpretation. The measure was developed to investigate the reliability of a new mathematics assessment method, of which an example is elaborated. The paper concludes with a worked-out example of psychiatrists diagnosing patients with multiple disorders. All calculations are provided as R script and an Excel sheet to facilitate access to the new statistic.
Informative Data Visualization with Raincloud Plots in JASP
Vincent L. Ott, Don van den Bergh, Bruno Boutin, Johnny van Doorn, František Bartoš, Nicholas Judd, Jordy van Langen, Luke Korthals, Rogier Kievit, Laura Groot & Eric-Jan Wagenmakers

Proper data visualization helps researchers draw correct conclusions from their data and facilitates a more complete and transparent report of the results. In factorial designs, so-called raincloud plots have recently attracted attention as a particularly informative data visualization technique; raincloud plots can simultaneously show summary statistics (i.e., a box plot), a density estimate (i.e., the cloud), and the individual data points (i.e., the raindrops). Here we first present a ‘raincloud quartet’ that underscores the added value of raincloud plots over the traditional presentation of means and confidence intervals. The added value of raincloud plots appears to be increasingly recognized: a focused literature review of plots in Psychonomic Bulletin & Review shows that 9% of plots in 2023 were raincloud plots. Another 29% of plots (vs. 2% in 2013) contained individual data points (i.e., raindrops), indicating a strong trend towards transparent and informative data visualization. To further encourage this trend and make raincloud plotting easy and practical for a broader group of researchers and students, we implemented a comprehensive suite of raincloud plots in JASP, an open-source statistics program with an intuitive graphical user interface. Examples from two factorial research designs illustrate how the JASP raincloud plots support a correct and comprehensive interpretation of the data.
Fabla: A voice-based ecological assessment method for securely collecting spoken responses to researcher questions
Deanna M. Kaplan, Santiago J. Arconada Alvarez, Roman Palitsky, Hyoann Choi, Gari D. Clifford, Melese Crozier, Boadie W. Dunlop, George H. Grant, Morgan N. Greenleaf, Leslie M. Johnson, Jessica Maples-Keller, Holly F. Levin-Aspenson, Jennifer S. Mascaro, Ariel McDowall, Nicole S. Pozzo, Charles L. Raison, Ali John Zarrabi, Barbara O. Rothbaum & Wilbur A. Lam
 This article reports on the validation of Fabla, a researcher-developed and university-hosted smartphone app that facilitates naturalistic and secure collection of participants’ spoken responses to researcher questions. Fabla was developed to meet the need for tools that (a) collect longitudinal qualitative data and (b) capture speech biomarkers from participants’ natural environments. This study put Fabla to its first empirical test using a repeated-measures experimental design in which participants (n = 87) completed a 1-week voice daily diary via the Fabla app, and an identical 1-week text-entry daily diary administered via Qualtrics, with diary method order counterbalanced and randomized. A preregistered analysis plan investigated (1) adherence, usability, and acceptability of Fabla, (2) concurrent validity of voice diaries (vs. text-entry diaries) by comparing linguistic features obtained via each diary method, and (3) differences in the strength of the association between linguistic features and their known psychological correlates when assessed by voice versus text-entry diary. Voice diaries yielded more than double the mean daily language volume (word count) compared to text-entry diaries and received high usability and acceptability ratings. Linguistic markers consistently associated with depression in prior research were significantly associated with depression symptoms when assessed via voice but not text-entry diaries, and the difference in correlation magnitude was significant. Word-count-adjusted linguistic patterns were highly correlated between diary methods, with statistically significant mean differences observed for some linguistic dimensions in the presence of these associations. Fabla is a promising tool for collecting high-quality speech data from participants’ naturalistic environments, overcoming multiple limitations of text-entry responding.
This article reports on the validation of Fabla, a researcher-developed and university-hosted smartphone app that facilitates naturalistic and secure collection of participants’ spoken responses to researcher questions. Fabla was developed to meet the need for tools that (a) collect longitudinal qualitative data and (b) capture speech biomarkers from participants’ natural environments. This study put Fabla to its first empirical test using a repeated-measures experimental design in which participants (n = 87) completed a 1-week voice daily diary via the Fabla app, and an identical 1-week text-entry daily diary administered via Qualtrics, with diary method order counterbalanced and randomized. A preregistered analysis plan investigated (1) adherence, usability, and acceptability of Fabla, (2) concurrent validity of voice diaries (vs. text-entry diaries) by comparing linguistic features obtained via each diary method, and (3) differences in the strength of the association between linguistic features and their known psychological correlates when assessed by voice versus text-entry diary. Voice diaries yielded more than double the mean daily language volume (word count) compared to text-entry diaries and received high usability and acceptability ratings. Linguistic markers consistently associated with depression in prior research were significantly associated with depression symptoms when assessed via voice but not text-entry diaries, and the difference in correlation magnitude was significant. Word-count-adjusted linguistic patterns were highly correlated between diary methods, with statistically significant mean differences observed for some linguistic dimensions in the presence of these associations. Fabla is a promising tool for collecting high-quality speech data from participants’ naturalistic environments, overcoming multiple limitations of text-entry responding.
Links to the institutional webpages associated with this project:
The Pictures by Category and Similarity (PiCS) database: A multidimensional scaling database of 1200 images across 20 categories
Arryn Robbins, Michael C. Hout, Ashley Ercolino, Joseph Schmidt, Hayward J. Godwin & Justin MacDonald

Visual similarity is an essential concept in vision science, and the methods used to quantify similarity have recently expanded in the areas of human-derived ratings and computer vision methodologies. Researchers who want to manipulate similarity between images (e.g., in a visual search, categorization, or memory task) often use the aforementioned methods, which require substantial, additional data collection prior to the primary task of interest. To alleviate this problem, we have developed an openly available database that uses multidimensional scaling (MDS) to model the similarity among 1200 items spread across 20 object categories, thereby allowing researchers to utilize similarity ratings within and between categories. In this article, we document the development of this database, including (1) collecting similarity ratings using the spatial arrangement method across two sites, (2) our computational approach with MDS, and (3) validation of the MDS space by comparing SpAM-derived distances to direct similarity ratings. The database and similarity data provided between items (and across categories) will be useful to researchers wanting to manipulate or control similarity in their studies. Link to dataset.
The Polish Vocabulary Size Test: A Novel Adaptive Test for Receptive Vocabulary Assessment
Longfei Zhang & Ping Chen

In the article, we present the Polish Vocabulary Size Test (PVST), a novel tool for assessing the receptive vocabulary size of both native and non-native Polish speakers. Based on item response theory and computerized adaptive testing, PVST dynamically adjusts to each test-taker’s proficiency level, ensuring high accuracy while keeping the test duration short. It is an up-to-date approach to vocabulary assessment and an alternative to LexTale (Lemhöfer & Broersma, 2012) and VST (Nation & Beglar, 2007) vocabulary tests.
We validated PVST on a large sample of 656 individuals, with 64% native and 37% non-native speakers. As expected, native Polish speakers demonstrated significantly larger vocabularies (mean = 75.125 words; range = 19.556–122.693) compared to non-native speakers (mean = 7165 words; range = 646–23.394). For native speakers, vocabulary size showed a strong positive correlation with age (r = .496, p < .001), meaning that vocabulary grows lifelong, but after the age of 30 the speed of lexical growth significantly slows down. Non-native speakers’ vocabulary, in turn, does not depend on age but on language exposure—reading, speaking, and listening. Non-native vocabulary is unlikely to reach the size of an adult native speaker’s. PVST is one of the first attempts to construct an effective vocabulary size test in Polish. The PVST is available online at myvocab.info/pl.
A neural network paradigm for modeling psychometric data and estimating IRT model parameters: Cross estimation network
Longfei Zhang & Ping Chen
 This paper presents a novel approach known as the cross estimation network (CEN) for fitting the datasets obtained from psychological or educational tests and estimating the parameters of item response theory (IRT) models. The CEN is comprised of two subnetworks: the person network (PN) and the item network (IN). The PN processes the response pattern of individual respondent and generates an estimate of the underlying ability, while the IN takes in the response pattern of individual item and outputs the estimates of the item parameters. Four simulation studies and an empirical study were comprehensively and rigorously conducted to investigate the performance of CEN on parameter estimation of the two-parameter logistic model under various testing scenarios. Results showed that CEN effectively fit the training data and produced accurate estimates of both person and item parameters. The trained PN and IN adhered to AI principles and acted as intelligent agents, delivering commendable evaluations for even unseen patterns of new respondents and items.
This paper presents a novel approach known as the cross estimation network (CEN) for fitting the datasets obtained from psychological or educational tests and estimating the parameters of item response theory (IRT) models. The CEN is comprised of two subnetworks: the person network (PN) and the item network (IN). The PN processes the response pattern of individual respondent and generates an estimate of the underlying ability, while the IN takes in the response pattern of individual item and outputs the estimates of the item parameters. Four simulation studies and an empirical study were comprehensively and rigorously conducted to investigate the performance of CEN on parameter estimation of the two-parameter logistic model under various testing scenarios. Results showed that CEN effectively fit the training data and produced accurate estimates of both person and item parameters. The trained PN and IN adhered to AI principles and acted as intelligent agents, delivering commendable evaluations for even unseen patterns of new respondents and items.
Code repository for implementing the CEN method: https://github.com/longfeizhangcode/CrossEstimationNetwor
Causal moderated mediation analysis: Methods and software
Xu Qin & Lijuan Wang
Research questions regarding how, for whom, and where a treatment achieves its effect on an outcome have become increasingly valued in substantive research. Such questions can be answered by causal moderated mediation analysis, which assesses the heterogeneity of the mediation mechanism underlying the treatment effect across individual and contextual characteristics. Various moderated mediation analysis methods have been developed under the traditional path analysis/structural equation modeling framework. One challenge is that the definitions of moderated mediation effects depend on statistical models of the mediator and the outcome, and no solutions have been provided when either the mediator or the outcome is binary, or when the mediator or outcome model is nonlinear. In addition, it remains unclear to empirical researchers how to make causal arguments of moderated mediation effects due to a lack of clarifications of the underlying assumptions and methods for assessing the sensitivity to violations of the assumptions. This article overcomes the limitations by developing general definition, identification, estimation, and sensitivity analysis for causal moderated mediation effects under the potential outcomes framework. We also developed a user-friendly R package moderate.mediation (https://cran.r-project.org/web/packages/moderate.mediation/index.html) that allows applied researchers to easily implement the proposed methods and visualize the initial analysis results and sensitivity analysis results. We illustrated the application of the proposed methods and the package implementation with a re-analysis of the National Evaluation of Welfare-to-Work Strategies (NEWWS) Riverside data.
Specificity ratings for Italian data
Marianna Marcella Bolognesi & Tommaso Caselli
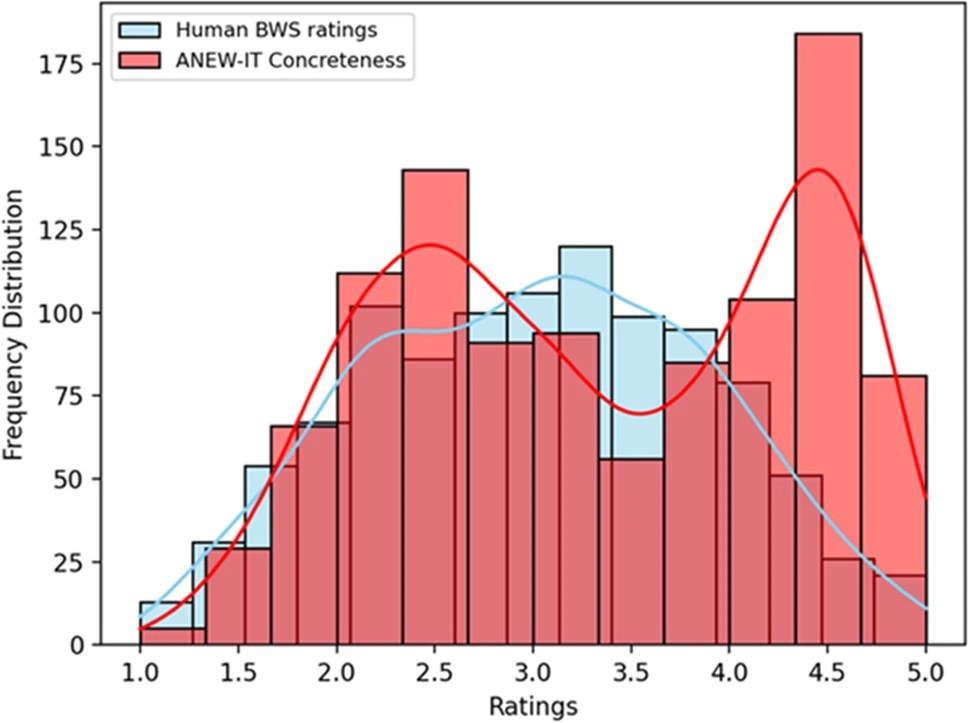
Abstraction enables us to categorize experience, learn new information, and form judgments. Language arguably plays a crucial role in abstraction, providing us with words that vary in specificity (e.g., highly generic: tool vs. highly specific: muffler). Yet, human-generated ratings of word specificity are virtually absent. We hereby present a dataset of specificity ratings collected from Italian native speakers on a set of around 1K Italian words, using the Best-Worst Scaling method. Through a series of correlation studies, we show that human-generated specificity ratings have low correlation coefficients with specificity metrics extracted automatically from WordNet, suggesting that WordNet does not reflect the hierarchical relations of category inclusion present in the speakers’ minds. Moreover, our ratings show low correlations with concreteness ratings, suggesting that the variables Specificity and Concreteness capture two separate aspects involved in abstraction and that specificity may need to be controlled for when investigating conceptual concreteness. Finally, through a series of regression studies we show that specificity explains a unique amount of variance in decision latencies (lexical decision task), suggesting that this variable has theoretical value. The results are discussed in relation to the concept and investigation of abstraction.
Data and materials are available here.
Analysing data from the psycholinguistic visual-world paradigm: Comparison of different analysis methods
Aine Ito & Pia Knoeferle
 In this paper, we discuss key characteristics and typical experiment designs of the visual-world paradigm and compare different methods of analysing eye-movement data. We discuss the nature of the eye-movement data visual-world studies and provide data analysis tutorials on ANOVA, t-tests, linear mixed-effects model, growth curve analysis, cluster-based permutation analysis, bootstrapped differences of time-series, generalised additive modelling, and divergence point analysis. The goal of the analysis comparison and tutorials is to enable psycholinguists to apply each analysis method to their own data. We discuss the advantages and disadvantages of each method and offer recommendations about how to select an appropriate method depending on the research question and the experiment design.
In this paper, we discuss key characteristics and typical experiment designs of the visual-world paradigm and compare different methods of analysing eye-movement data. We discuss the nature of the eye-movement data visual-world studies and provide data analysis tutorials on ANOVA, t-tests, linear mixed-effects model, growth curve analysis, cluster-based permutation analysis, bootstrapped differences of time-series, generalised additive modelling, and divergence point analysis. The goal of the analysis comparison and tutorials is to enable psycholinguists to apply each analysis method to their own data. We discuss the advantages and disadvantages of each method and offer recommendations about how to select an appropriate method depending on the research question and the experiment design.
A modularity design approach to behavioral research with immersive virtual reality: A SkyrimVR-based behavioral experimental framework
Ze-Min Liu & Yu-Hsin Chen
 Given the prevalence and increased interest to employ virtual reality technology in human behavioral research. An increase in the number of toolkits, toolbox, frameworks, and platforms to provide user’s a means to conduct human behavioral research in VR has been seen over the past decade. Despite this, numerous factors, such as limited fundings, personnel, time, and programming/art design proficiency continue to impede many users from efficiently carrying out behavioral experiments in VR. Hence, 5 years ago we began to conceptualize, create, and gradually develop and test a SkyrimVR-based behavioral experimental framework (SkyBXF) module that could fully utilize the rich resources provided by SkyrimVR and editable via Creation Kit. The goal was to provide researchers and students with minimal programming proficiency, 3D environment development expertise, time, and personnel; A ready-to-go behavioral experiment template to swiftly establish realistic virtual worlds that can be further customized for specific experimental needs. The initial thoughts for this project were something equivalent to Microsoft Powerpoint for creating slideshows, but for VR behavioral experiments. Where one could simply “install” SkyBXF and “load” a SkyBXF template and get right to conducting VR behavioral experiments! For more details on how to start a VR behavioral experiment using SkyBXF and the basic functions/options/controls of classic human behavior experiments, scan the QR code to visit our Github page.
Given the prevalence and increased interest to employ virtual reality technology in human behavioral research. An increase in the number of toolkits, toolbox, frameworks, and platforms to provide user’s a means to conduct human behavioral research in VR has been seen over the past decade. Despite this, numerous factors, such as limited fundings, personnel, time, and programming/art design proficiency continue to impede many users from efficiently carrying out behavioral experiments in VR. Hence, 5 years ago we began to conceptualize, create, and gradually develop and test a SkyrimVR-based behavioral experimental framework (SkyBXF) module that could fully utilize the rich resources provided by SkyrimVR and editable via Creation Kit. The goal was to provide researchers and students with minimal programming proficiency, 3D environment development expertise, time, and personnel; A ready-to-go behavioral experiment template to swiftly establish realistic virtual worlds that can be further customized for specific experimental needs. The initial thoughts for this project were something equivalent to Microsoft Powerpoint for creating slideshows, but for VR behavioral experiments. Where one could simply “install” SkyBXF and “load” a SkyBXF template and get right to conducting VR behavioral experiments! For more details on how to start a VR behavioral experiment using SkyBXF and the basic functions/options/controls of classic human behavior experiments, scan the QR code to visit our Github page.
OWLET: An automated, open-source method for infant gaze tracking using smartphone and webcam recordings
Denise M. Werchan, Moriah E. Thomason & Natalie H. Brito
Groundbreaking insights into the origins of the human mind have been garnered through the study of eye movements in preverbal subjects who are unable to explain their thought processes. Developmental research has largely relied on in-lab testing with trained experimenters. This constraint provides a narrow window into infant cognition and impedes large-scale data collection in families from diverse socioeconomic, geographic, and cultural backgrounds. Here we introduce a new open-source methodology for automatically analyzing infant eye-tracking data collected on personal devices in the home. Using algorithms from computer vision, machine le arning, and ecological psychology, we develop an online webcam-linked eye tracker (OWLET) that provides robust estimation of infants’ point of gaze from smartphone and webcam recordings of infant assessments in the home. We validate OWLET in a large sample of 7-month-old infants (N = 127) tested remotely, using an established visual attention task. We show that this new method reliably estimates infants’ point-of-gaze across a variety of contexts, including testing on both computers and mobile devices, and exhibits excellent external validity with parental-report measures of attention. Our platform fills a significant gap in current tools available for rapid online data collection and large-scale assessments of cognitive processes in infants. Remote assessment addresses the need for greater diversity and accessibility in human studies and may support the ecological validity of behavioral experiments. This constitutes a critical and timely advance in a core domain of developmental research and in psychological science more broadly.
arning, and ecological psychology, we develop an online webcam-linked eye tracker (OWLET) that provides robust estimation of infants’ point of gaze from smartphone and webcam recordings of infant assessments in the home. We validate OWLET in a large sample of 7-month-old infants (N = 127) tested remotely, using an established visual attention task. We show that this new method reliably estimates infants’ point-of-gaze across a variety of contexts, including testing on both computers and mobile devices, and exhibits excellent external validity with parental-report measures of attention. Our platform fills a significant gap in current tools available for rapid online data collection and large-scale assessments of cognitive processes in infants. Remote assessment addresses the need for greater diversity and accessibility in human studies and may support the ecological validity of behavioral experiments. This constitutes a critical and timely advance in a core domain of developmental research and in psychological science more broadly.
 PLAViMoP database: A new continuously assessed and collaborative 3D point-light display dataset
PLAViMoP database: A new continuously assessed and collaborative 3D point-light display dataset
Christel Bidet-Ildei, Victor Francisco, Arnaud Decatoire, Jean Pylouster & Yannick Blandin
It was more than 45 years ago that Gunnar Johansson invented the point-light display technique. This showed for the first time that
kinematics is crucial for action recognition, and that humans are very sensitive to their conspecifics’ movements. As a result, many of today’s researchers use point-light displays to better understand the mechanisms behind this recognition ability. In this paper, we propose PLAViMoP, a new database of 3D point-light displays representing everyday human actions (global and fine-motor control movements), sports movements, facial expressions, interactions, and robotic movements. Access to the database is free, at https://plavimop.prd.fr/en/motions. Moreover, it incorporates a search engine to facilitate action retrieval. In this paper, we describe the construction, functioning, and assessment of the PLAViMoP database. Each sequence was analyzed according to four parame ters: type of movement, movement label, sex of the actor, and age of the actor. We provide both the mean scores for each assessment of each point-light display, and the comparisons between the different categories of sequences. Our results are discussed in the light of the literature and the suitability of our stimuli for research and applications.
ters: type of movement, movement label, sex of the actor, and age of the actor. We provide both the mean scores for each assessment of each point-light display, and the comparisons between the different categories of sequences. Our results are discussed in the light of the literature and the suitability of our stimuli for research and applications.
Quantifying social semantics: An inclusive definition of socialness and ratings for 8388 English words

It has been proposed that social experience plays an important role in the grounding of concepts, and socialness has been proffered as a fundamental organisational principle underpinning semantic representation in the human brain. However, the empirical support for these hypotheses is limited by inconsistencies in the way socialness has been defined and measured. To further advance theory, the field must establish a clearer working definition, and research efforts could be facilitated by the availability of an extensive set of socialness ratings for individual concepts. Therefore, in the current work, we employed a novel and inclusive definition to test the extent to which socialness is reliably perceived as a broad construct, and we report socialness norms for over 8000 English words, including nouns, verbs, and adjectives. Our inclusive socialness measure shows good reliability and validity, and our analyses suggest that the socialness ratings capture aspects of word meaning which are distinct to those measured by other pertinent semantic constructs, including concreteness and emotional valence. Finally, in a series of regression analyses, we show for the first time that the socialness of a word’s meaning explains unique variance in participant performance on lexical tasks. Our dataset of socialness norms has considerable item overlap with those used in both other lexical/semantic norms and in available behavioural mega-studies. They can help target testable predictions about brain and behaviour derived from multiple representation theories and neurobiological accounts of social semantics.
The database is here https://osf.io/2dqnj/
Development of the Abbreviated Technology Anxiety Scale (ATAS)
 Matthew L. Wilson, Anne Corinne Huggins‐Manley, Albert D. Ritzhaupt, Krista Ruggles
Matthew L. Wilson, Anne Corinne Huggins‐Manley, Albert D. Ritzhaupt, Krista Ruggles
The ubiquity of technology in contemporary society causes some to develop anxiety when forced to these tools, especially in academic contexts. To address this, we developed the Abbreviated Technology Anxiety Scale, or ATAS, a short, low-stakes 11-item scale for measuring technology anxiety. This article presents the scale and the multiphase process for its development through the gathering of validity evidence. ATAS scores were found to have an internally consistent structure, as well as correlate with other known measures of technology and anxiety.

Empirica: a virtual lab for high-throughput macro-level experiments
Abdullah Almaatouq, Joshua Becker, James P. Houghton, Nicolas Paton, Duncan J. Watts & Mark E. Whiting
Virtual labs allow researchers to design high-throughput and macro-level experiments that are not feasible in traditional in-person physical lab settings. Despite the increasing popularity of online research, researchers still face many technical and logistical barriers when designing and deploying virtual lab experiments. While several platforms exist to facilitate the development of virtual lab experiments, they typically present researchers with a stark trade-off between usability and functionality. We introduce Empirica: a modular virtual lab that offers a solution to the usability-functionality trade-off by employing a “flexible defaults” design strategy. This strategy enables us to maintain complete “build anything” flexibility while offering a development platform that is accessible to novice programmers. Empirica’s architecture is designed to allow for parameterizable experimental designs, reusable protocols, and rapid development. These features will increase the accessibility of virtual lab experiments, remove barriers to innovation in experiment design, and enable rapid progress in the understanding of human behavior.

StimuliApp: Psychophysical tests on mobile devices
Rafael Marin-Campos, Josep Dalmau, Albert Compte, & Daniel Linares
Mobile handheld devices, such as smartphones or tablets, can now run psychophysical tests using StimuliApp. StimuliApp is an open-source application that includes many templates for stimuli creation (including gradients, gratings, random-dots, texts, and tones). The application also allows for the presentation of images, videos, and audio. And importantly, the timing is precise.

Quaddles: A multidimensional 3-D object set.
Marcus Watson, Benjamin Voloh, Milad Maghidazeh, & Thilo Womelsdorf
Studies of visual cognition often require novel 3D objects that can be defined in a parametric feature space. This article presents a new parametrically-defined multi-featured 3D object set, and provides a link to download the scripts and a detailed manual used to generate them, either as 3D .fbx files or as PNG files showing the objects from any desired angle (I have attached a few representative examples of the PNGs). At present the scripts allow the creation of over 250,000 objects that differ along several dimensions (e.g. colour, surface pattern, body shape, body texture, etc), and can easily be modified to include additional dimensions or new values along those dimensions.

Mental chronometry in the pocket? Timing accuracy of web applications on touchscreen and keyboard devices
Thomas Pronk, Reinout W. Wiers, Bert Molenkamp & Jaap Murre
Web applications can implement procedures for studying the speed of mental processes (mental chronometry) and can be administered via web browsers on most commodity desktops, laptops, smartphones, and tablets. The results of this research offer some guidelines as to what methods may be most accurate and what mental chronometry paradigms may suitably be administered via web applications. In controlled circumstances, as can be realized in a lab setting, very accurate stimulus timing and moderately accurate RT measurements could be achieved on both touchscreen and keyboard devices, though RTs were consistently overestimated. In uncontrolled circumstances, such as researchers may encounter online, stimulus presentation may be less accurate, especially when brief durations are requested (of up to 100 ms).

The “Small World of Words” English word association norms for over 12,000 cue words.
Simon De Deyne, Danielle Navarro, Amy Perfors, Marc Brysbaert, Gert Storms
Word associations have been used widely in psychology, but the validity of their application strongly depends on the number of cues included in the study and the extent to which they probe all associations known by an individual. In this work, we address both issues by introducing a new English word association dataset. We describe the collection of word associations for over 12,000 cue words, currently the largest such English-language resource in the world. Our procedure allowed subjects to provide multiple responses for each cue, which permits us to measure weak associations.

Validation of a matrix reasoning task for mobile devices
Many cognitive tasks have been adapted for tablet-based testing, but tests to assess nonverbal reasoning ability, as measured by matrix-type problems that are suited to repeated testing, have yet to be adapted for and validated on mobile platforms. We developed the University of California Matrix Reasoning Task (UCMRT)—a short, user-friendly measure of abstract problem solving with three alternate forms that works on tablets and other mobile devices and that is targeted at a high-ability population frequently used in the literature (i.e., college students). UCMRT is reliable and has adequate convergent and external validity. UCMRT is self-administrable, freely available for researchers, facilitates repeated testing of fluid intelligence, and resolves numerous limitations of existing matrix tests.
 Systematic mappings between semantic categories and types of iconic representations in the manual modality: A normed database of silent gesture
Systematic mappings between semantic categories and types of iconic representations in the manual modality: A normed database of silent gesture
Gerardo Ortega & Aslı Özyürek
An unprecedented number of empirical studies have shown that iconic gestures—those that mimic the sensorimotor attributes of a referent—contribute significantly to language acquisition, perception, and processing. However, there has been a lack of normed studies describing generalizable principles in gesture production and in comprehension of the mappings of different types of iconic strategies. We report an empirically-validated database that includes a list of the most systematic silent gestures in the group of participants, a notation of the form of each gesture based on four features (hand configuration, orientation, placement, and movement), each gesture’s mode of representation, iconicity ratings, and professionally filmed videos that can be used for experimental and clinical endeavors.
 SOLID-Similar object and lure image database
SOLID-Similar object and lure image database
Stimulus selection is a critical part of experimental designs in the cognitive sciences. Quantifying and controlling item similarity using a unified scale provides researchers with the tools to eliminate item-dependent effects and improve reproducibility. Here we present a novel Similar Object and Lure Image Database (SOLID) that includes 201 categories of grayscale objects, with approximately 17 exemplars per set. Unlike existing databases, SOLID offers both a large number of stimuli and a considerable range of similarity levels. Enabling this degree of control over similarity is critical for high-level studies of memory and cognition, and combining this strength with the option to use it across many trials will allow research questions to be addressed using neuroimaging techniques.
 Motor content norms for 4,565 verbs in Spanish
Motor content norms for 4,565 verbs in Spanish
Embodiment theory suggests that, during the processing of words related to movement, as in the case of action verbs, somatotopic activation is produced in the motor and premotor cortices. We developed a database of 4,565 verbs in Spanish through a survey filled out by 152 university students to provide a standardized data base concerning the motor content of Spanish verbs. The value for the motor content was obtained by calculating the average value from the answers of the participants. The database and the raw responses of the participants can be downloaded from this website: https://inco.grupos.uniovi.es/enlaces.

LADEC: The Large Database of English Compounds
The Large Database of English Compounds (LADEC) consists of over 8,000 English words that can be parsed into two constituents that are free morphemes, making it the largest existing database specifically for use in research on compound words. Both monomorphemic (e.g., wheel) and multimorphemic (e.g., teacher) constituents were used. The items were selected from a range of sources, including CELEX, the English Lexicon Project, the British Lexicon Project, the British National Corpus, and Wordnet, and were hand-coded as compounds (e.g., snowball). Participants rated each compound in terms of how predictable its meaning is from its parts, as well as the extent to which each constituent retains its meaning in the compound. In addition, we obtained linguistic characteristics that might influence compound processing (e.g., frequency, family size, and bigram frequency). The database can be downloaded from https://era.library.ualberta.ca (search term: LADEC), formatted as text (.csv) or as a Stata datafile.

{kind=link}